Basic Usage of the tyssue library¶
Easy creation of a 2D epithelial sheet¶
[1]:
%matplotlib inline
# Core object
from tyssue import Sheet
# Simple 2D geometry
from tyssue import PlanarGeometry as geom
# Visualisation
from tyssue.draw import sheet_view
sheet = Sheet.planar_sheet_2d('basic2D', nx=6, ny=7,
distx=1, disty=1)
geom.update_all(sheet)
[2]:
fig, ax = sheet_view(sheet, mode="2D")
fig.set_size_inches(8, 8)
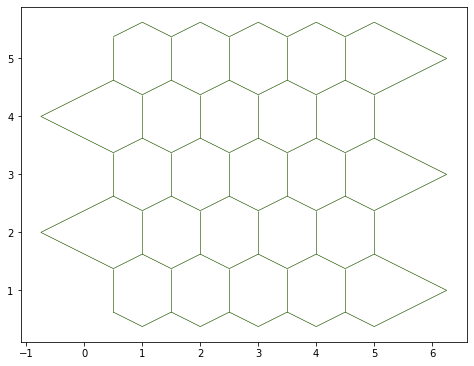
We can have a cleaner, better order sheet with the sanitize method:
[3]:
# Give the tissue a nice hear cut ;)
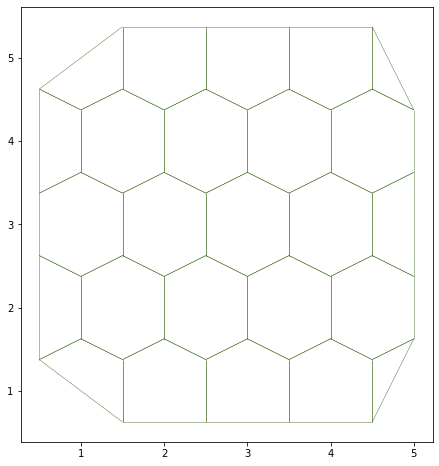
sheet.sanitize(trim_borders=True, order_edges=True)
geom.update_all(sheet)
[4]:
fig, ax = sheet_view(sheet, mode="2D")
fig.set_size_inches(8, 8)
A remark on the half-edge data structure¶
As is represented in the above graph, each edge between two cells is composed of two half-edges (only one half-edge is present in the border ones). This makes it easier to compute many cell-specific quantities, as well as keeping a well oriented mesh. This is inspired by CGAL polyhedral surfaces.
Datasets and specifications¶
The data associated with the mesh displayed above, i.e. the points positions, the connectivity information, etc. is stored in pandas DataFrame objects, hold together in the datasets dictionnary.
Depending on the geometry, the following dataframes are populated: * datasets["edge"] or sheet.edge_df: The edge related dataframe contains - the connectivity information: source and target vertices, associated face and (for thick tissues) the associated cell body. - geometry data associated with the edge, such as its length - any suplemental data, such as a color or a dynamical parameter (an elasticity for example)
datasets["vert"]orsheet.vert_df: The vertices related dataframe. In the apical junction mesh above, those are the vertices at the cells junctions. It usually holds the coordinates of the points, and geometry or dynamical data.datasets["face"]orsheet.face_df: The faces related dataframe. For a thin, 2D tissue, this corresponds to a cell of the epithelium, delimited by its edges. In thick, 3D models, one cell has several faces (the apical, sagittal and basal ones for a 3D monolayer, for example).datasets["cell"]orsheet.cell_df: The cells related dataframe, only for 3D, thick, epithelium. Each cell have several faces.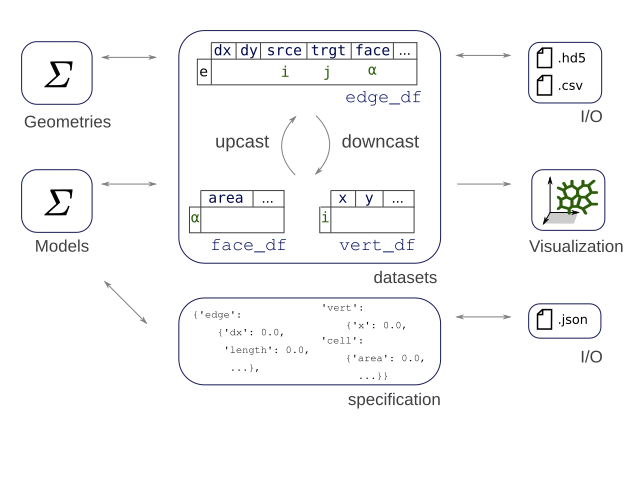
[5]:
for element, data in sheet.datasets.items():
print(element, ':', data.shape)
vert : (48, 3)
edge : (128, 20)
face : (25, 6)
[6]:
sheet.datasets['edge'].head()
[6]:
| trgt | nz | length | face | srce | dx | dy | sx | sy | tx | ty | fx | fy | ux | uy | rx | ry | sub_area | is_valid | phi | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| edge | ||||||||||||||||||||
| 0 | 30 | 0.28125 | 0.750000 | 0 | 28 | 0.0 | 0.75 | 1.5 | 0.625 | 1.5 | 1.375 | 1.125 | 1.250 | 0.0 | 0.0 | 0.375 | -0.625 | 0.140625 | True | -0.643501 |
| 1 | 9 | 0.15625 | 0.559017 | 0 | 30 | -0.5 | 0.25 | 1.5 | 1.375 | 1.0 | 1.625 | 1.125 | 1.250 | 0.0 | 0.0 | 0.375 | 0.125 | 0.078125 | True | 0.643501 |
| 2 | 5 | 0.21875 | 0.559017 | 0 | 9 | -0.5 | -0.25 | 1.0 | 1.625 | 0.5 | 1.375 | 1.125 | 1.250 | 0.0 | 0.0 | -0.125 | 0.375 | 0.109375 | True | 1.570796 |
| 3 | 28 | 0.34375 | 1.250000 | 0 | 5 | 1.0 | -0.75 | 0.5 | 1.375 | 1.5 | 0.625 | 1.125 | 1.250 | 0.0 | 0.0 | -0.625 | 0.125 | 0.171875 | True | 1.570796 |
| 4 | 43 | 0.37500 | 0.750000 | 1 | 29 | 0.0 | 0.75 | 2.5 | 0.625 | 2.5 | 1.375 | 2.000 | 1.125 | 0.0 | 0.0 | 0.500 | -0.500 | 0.187500 | True | -0.643501 |
The edge_df dataframe contains most of the information. In particular, each time the geometry is updated with the geom.update_all(sheet) function, the positions of the source and target vertices of each edge are copied to the "sx", "sy" and "tx", "ty" columns, respectively.
[7]:
sheet.face_df.head()
[7]:
| y | is_alive | perimeter | area | x | num_sides | |
|---|---|---|---|---|---|---|
| face | ||||||
| 0 | 1.250000 | 1 | 3.118034 | 0.5000 | 1.125000 | 4 |
| 1 | 1.125000 | 1 | 3.618034 | 0.8750 | 2.000000 | 5 |
| 2 | 1.125000 | 1 | 3.618034 | 0.8750 | 3.000000 | 5 |
| 3 | 1.125000 | 1 | 3.618034 | 0.8750 | 4.000000 | 5 |
| 4 | 1.208333 | 1 | 2.427051 | 0.1875 | 4.666667 | 3 |
We can use all the goodies from pandas DataFrames objects. For example, it is possible to compute the average edge length for each face like so:
[8]:
sheet.edge_df.groupby('face')['length'].mean().head()
[8]:
face
0 0.779508
1 0.723607
2 0.723607
3 0.723607
4 0.809017
Name: length, dtype: float64
Specifications are defined as a nested dictionnary, sheet.specs. For each element, the specification defines the columns of the corresonding DataFrame and their default values. An extra key at the root of the specification is called "settings", and can hold specific parameters, for example the arguments for an energy minimization procedure.
[9]:
sheet.specs
[9]:
{'edge': {'trgt': 0,
'nz': 0.0,
'length': 1.0,
'face': 0,
'srce': 0,
'dx': 0.0,
'dy': 0.0,
'sx': 0.0,
'sy': 0.0,
'tx': 0.0,
'ty': 0.0,
'fx': 0.0,
'fy': 0.0,
'ux': 0.0,
'uy': 0.0},
'vert': {'y': 0.0, 'is_active': 1, 'x': 0.0},
'face': {'y': 0.0,
'is_alive': 1,
'perimeter': 0.0,
'area': 0.0,
'x': 0.0,
'num_sides': 6},
'settings': {'geometry': 'planar'}}
It is possible to update dynamically the data structure. For example, let’s assume we want to put quasi-static model to minimize energy for the tyssue. For this we need three things. * A specification dictionnary with the required data * A model * A solver
[10]:
from tyssue.config.dynamics import quasistatic_plane_spec
from tyssue.dynamics.planar_vertex_model import PlanarModel
from tyssue.solvers import QSSolver
# Update the specs
sheet.update_specs(quasistatic_plane_spec())
# Find energy minimum
solver = QSSolver()
res = solver.find_energy_min(sheet,
geom,
PlanarModel)
print("Successfull gradient descent? ", res['success'])
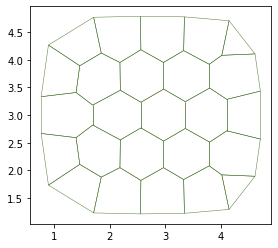
fig, ax = sheet_view(sheet)
/home/docs/checkouts/readthedocs.org/user_builds/tyssue/conda/stable/lib/python3.7/site-packages/tyssue/utils/utils.py:35: FutureWarning: Support for multi-dimensional indexing (e.g. `obj[:, None]`) is deprecated and will be removed in a future version. Convert to a numpy array before indexing instead.
df_nd = df[:, None]#np.asarray(df).repeat(ndim).reshape((df.size, ndim))
Successfull gradient descent? True
Upcasting and downcasting data¶
Upcasting¶
Geometry or physics computations often require to access for example the cell related data on each of the cell’s edges. The Epithelium class and its derivatives defines utilities to make this, i.e copying the area of each face to each of its edges:
[11]:
print('Faces associated with the first edges:')
print(sheet.edge_df['face'].head())
print('\n')
# First edge associated face
face = sheet.edge_df.loc[0, 'face']
print('Area of cell # {}:'.format(int(face)))
print(sheet.face_df.loc[face, 'area'])
print('\n')
print('Upcasted areas over the edges:')
print(sheet.upcast_face(sheet.face_df['area']).head())
Faces associated with the first edges:
edge
0 0
1 0
2 0
3 0
4 1
Name: face, dtype: int64
Area of cell # 0:
0.43544708469079896
Upcasted areas over the edges:
edge
0 0.435447
1 0.435447
2 0.435447
3 0.435447
4 0.562091
Name: area, dtype: float64
The values have indeed be upcasted. This can also be done with the source and target vertices (sheet.upcast_srce, sheet.upcast_trgt) and cells in the 3D case (sheet.upcast_cell).
Downcasting¶
This is usually done by groupby operations as shown above. Syntactic sugar is available for summation, e.g. over every edges with a given source:
[12]:
sheet.sum_srce(sheet.edge_df['line_tension']).head()
[12]:
| line_tension | |
|---|---|
| srce | |
| 0 | 0.36 |
| 1 | 0.24 |
| 2 | 0.24 |
| 3 | 0.36 |
| 4 | 0.36 |
Input and Output¶
The ‘native’ format is to save the datasets to hdf5 via `pandas.HDFStore <https://pandas.pydata.org/pandas-docs/stable/cookbook.html#hdfstore>`__. The io.obj also provides functions to export the junction mesh or triangulations to the wavefront OBJ format (requires vispy), for easy import in 3D software such as Blender.
Here is the code to save the data in wavefront OBJ:
obj.save_junction_mesh('junctions.obj', sheet)
The standard data format for the datasets is HDF:
[13]:
from tyssue.io import hdf5
[14]:
hdf5.save_datasets('tmp_data.hdf5', sheet)
[15]:
dsets = hdf5.load_datasets('tmp_data.hdf5')
sheet2 = Sheet('reloaded', dsets)
[16]:
!rm tmp_data.hdf5
Specs can be saved as json files:
[17]:
import json
with open("tmp_specs.json", "w") as jh:
json.dump(sheet.specs, jh)
And reloaded accordingly
[18]:
with open("tmp_specs.json", "r") as jh:
specs = json.load(jh)
sheet2.update_specs(specs, reset=False)
[19]:
!rm tmp_specs.json
[ ]:
[ ]: